A Concrete Question: Polynomial Regression vs. Neural Nets
Enthusiasm Curbed, June 10, 2019
Overview
I take a look at a paper claiming to show that polynomial regression has superior/competitive performance against neural networks. A curious table catches my eye, thus leading me to believe that the authors did not perform a fair benchmark of the two methods.
UPDATE: Matloff nicely responded, and there was indeed an error in the paper. I am still not completely satisfied with the response, but I guess this is a step in the right direction. The twitter discussion between us is here .
Ahh that paper I meant to reread...
I don't know nearly as much statistics as I should, yet -- for some odd reason -- I enjoy watching Bayesians and Frequentists argue about issues I don't fully understand. One of the best ways to observe these discussions is to follow Frank Harrell on Twitter. To be fair, Frank often also posts about interesting discussions on DataMethods and talks about statistical issues that interest me too. Generally, his discussions have led me to learn a surprising amount of statistics through Twitter.
Recently, he posted his slides from a talk he gave entitled Controversies in Predictive Modeling, Machine Learning, and Validation . I'm not going to pretend that I understand everything in the slides, though a lot of it is interesting. There are some statements I only sort of understand (it's been a while since I read about the Laplace distriubtion). There are some statements I have mixed feelings about. And there is even one statement that led me to write this blog post.
The aformentioned "trigger" is found in the "Machine Learning" portion of his slides and really involves two statements: "deep learning ≡ neural network" and "neural network ≡ polynomial regression -- Matloff". The first is pretty standard, but the second statement caught my eye. I remember skimming the original paper, Polynomial Regression As an Alternative to Neural Nets by Cheng, Khomtchouk, Matloff, and Mohanty last summer but haven't thought about it much since. Matloff's blog post linked in the slides created a lot of discussion, with over 80 comments on the blog. Furthermore, if the article is still being quoted by prominent figures in the medical statistics community, maybe there is more to the article than I originally thought. So I decided to look at it again.
Uhh that seems low?
In Matloff's blog post, he makes some pretty big claims regarding his idea that neural networks are essentially polynomial regression (NNAEPR, as he calls it):
As someone interested in using stuff that works, those are some pretty strong statements. Most of the comments on the original paper were people arguing theory such as universal function approximators and such. However, if this really had such big practical implications, why weren't more people talking about use?
- NNAEPR suggests that one may abandon using NNs altogether, and simply use PR instead.
- We investigated this on a wide variety of datasets, and found that in every case PR did as well as, and often better than, NNs.
I decided to skim through the paper myself, and see if the practical results were really that good. I can't say I have an abundance of time to keep up with all of the literature these days, so as with a lot of people, I started with the tables and relevant results. Therefore, I will fully disclose now that I did not read the entire paper. Thus, it might be irresponsible of me to even write this post, and I shall try not to pass too much judgement. However, I probably won't read the rest of the paper until someone can explain to me my results below.
What especially caught my eye is the following table:
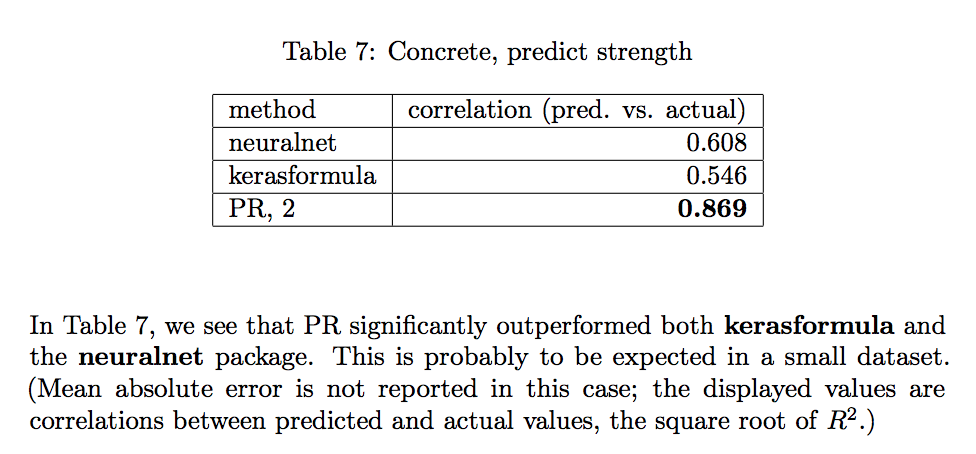
The answer frustrates me because I obtained \(r=0.925\) with a 95% CI of (0.897, 0.945) on an independent test set in under 2 minutes of training. This didn't involve extensive hyperparameter tuning or a crazy architecture. I used the simple PyTorch DNN architecture that I use for many simple applications and used fastai for training. All details are in the attached Google Colab notebook, where anyone can run the code if they wish. As you can see from the table above, my results beat "polyreg" and drastically outperform the authors' own neural net benchmarks. Do I think this is because I am an amazing magician of deep learning? No -- even though I wish that explanation were true. I think what really happened is a bit more frustrating.
I think what probably happened here is what happens in most papers of the form, "here's a new method that outperforms the other ones." The authors try really hard to get good results with their own method and don't care as much about optimizing the results of the other methods. In fact, it is often against one's interest to care about optimizing the performance of the other methods. It's much easier to feel tall if you live among the Oompa Loompas, just don't get any ideas that you are going to dunk a basketball (I cannot explain how this analogy popped into my head).
To be fair, I have no idea if this is what happened here. I only checked one dataset, though the difference in results was quite drastic. Furthermore, it's not truly a fair test because I am not sure how the authors split the data. Here's all I could find in the paper:
The dataset was split into training and test sets, with the number of cases for the latter being the min(10000,number of rows in full set).I don't quite know what this means. The concrete dataset is 1030 rows, so how is the test set just all of the rows? Are they implying they use a CV or nested-CV scheme to do this (in which case, where are the error bars)? Please let me know if I am just being dumb here.
Maybe someone can explain it?
I obviously have some questions about this paper. To his credit, Norm Matloff has been very responsive to comments on his blog post and perhaps will assuage my doubts. Furthermore, I am not saying that the paper is categorically of no use. Maybe there is value to thinking of neural nets as polynomial regression. As Dan Simpson writes on Andrew Gelman's Blog:
But the whole story–that neural networks can also be understood as being quite like polynomial regression and that analogy can allow us to improve our NN techniques–is the sort of story that we need to tell to understand how to make these methods better in a principled way.Dan also notes a few problems he has with the paper itself, which you should read about in the post and are quite different with my own complaints.
Going off Dan's point, I just really hope this story we are telling ourselves is somewhat true. But I guess Columbus found America by convincing himself the world was much smaller than all scientific evidence suggested. So maybe it will at least be a useful fiction? For now, I'll stick with my handy DNN when it comes to concrete results.